AI Concepts Made Easy
Convolutional Neural Networks (CNN)
Edge detection
Interactive Sobel Filter
The Interactive Sobel Filter demonstrates the fundamental operation of the Convolutional Layer—the first and most important step in a CNN. The Sobel filter is a classic kernel (a small matrix of weights) designed specifically to detect edges in an image.
How it Works in the Demo:
The Filter (Kernel): The demo uses two specialized $3 \times 3$ filters:
Vertical Sobel Filter: Used to detect vertical edges.
Horizontal Sobel Filter: Used to detect horizontal edges.
Convolution: The system slides each filter over your input image, performing a dot product (multiplication and summation) at every position. This operation creates a Feature Map.
Feature Map Output: The resulting map lights up (shows high values) only where the corresponding edge is detected. If the Vertical Filter runs over a vertical line, the output is high. If it runs over a horizontal line, the output is near zero.
Edge Magnitude: The two maps are mathematically combined to produce a final, rotation-agnostic map that shows the strength of all edges in the image.
By letting you draw an image and watch the math happen pixel-by-pixel, this demo builds the intuition for how CNNs transform raw pixel data into meaningful, abstract features like edges, which they use for later classification.


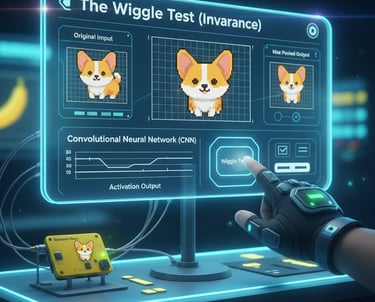
The "Wiggle Test" (Translational Invariance)
The "Wiggle Test" is an interactive demonstration of translational invariance, the crucial property that the Max Pooling layer adds to a Convolutional Neural Network (CNN).
Translational invariance means that a network can still recognize a feature (like an eye, an edge, or a corner) even if that feature is shifted or "wiggled" slightly in the input image.
How it Works in the Demo:
Input: You define a simple feature (e.g., a small line) on the input grid.
Wiggle: When you click the shift buttons, the feature moves one pixel (a "wiggle").
Result: The Max Pooling layer works by taking the maximum value within a fixed window (e.g., $2 \times 2$). As long as the feature remains within that $2 \times 2$ window after the shift, the maximum value selected for the output remains unchanged.
Conclusion: The output of the final Max Pool layer is stable (invariant) despite the movement of the input. This makes CNNs highly robust to minor differences in object placement, which is essential for tasks like object recognition.

AIML-LEARN PVT.LTD.
Location
Support@aimllearn.com
Senani , 3rd floor,
12/37, Ex-Servicemen Colony,
Paud Road, Pune 411038
Maharashtra, India.
Contact : +91 7758970797
©Aiml-learn pvt.ltd. 2024. All rights reserved.